
Tiny Intro Toolbox Thread
category: code [glöplog]
I was imagining things. :) The one-write version is not any faster.
Is there something that can be assumed in general about which registers are preserved by DOS calls?
Is there something that can be assumed in general about which registers are preserved by DOS calls?


On a real dos you can just trace into the interrupts and look if the service routines preserve explicitly (pusha, pushf, push *s), never tried that on a dosbox though ^^
I was curious because evidently the WRITE call (int 21h, AH=40h) preserves BX. But this doesn't seem to be mentioned in any of those docs.
@Blueberry: i debugged into int21h for AH = 3Ch (virtual box, msdos 6.22, debug.exe, "t" & "p") and from what i saw, it pushed/popped everything it changes inside, besides the return values. Of course i can't cover every case but there is also this : "If calls are made by the approved method the contents of all registers are preserved through calls". That's also what one would assume intuitively, right?
Also, german source : "Generell gilt, dass die Registerinhalte vor dem Aufruf von INT21h-Funktionen nicht gesichert werden müssen, denn sie bleiben erhalten. Das gilt natürlich nicht für die Register, in denen die betreffende INT21h-Funktion Werte zurückgibt."
You can't rely on this behavior because different versions of DOS can do slightly different things. Don't assume what you see in DOS 6.22 works in DOSBox, or FreeDOS, or DOS 3.3, or MS-DOS 7.x (ie. what comes with Win9x).
Most DOS calls are supposed to preserve all regs that don't return results, but many DOSes trash BP. Ralf Brown's Interrupt List has a few known gotchas.
Most DOS calls are supposed to preserve all regs that don't return results, but many DOSes trash BP. Ralf Brown's Interrupt List has a few known gotchas.

Do you want High Resolution and PC speaker in 32 bytes?
> here you go <
> here you go <
When tinkering with "secret modes" i found the not-so-secret mode 0x6A which i give too little attention since it didnt work in dosbox. Apparently this allows 800x600 resolution with no overhead, applied here to "dragon fade"
It might be overlooked, but if you are interested in coding your 256 Byter with the help of SSE (didn't see much of that yet for tiny intros...) to get some serious speedup over an FPU version you can check out Frigo's lovely Kali-set and my SSE (level 4.1 needed) implementation in that product thread. Thanks also to TomCat for additional help.
The speedup of the double pixel interleaved loop is > 400% while keeping the size, so it actually makes sense for that kind of algorithm. For others may be the overhead could be too much.
What keeps me puzzled is how to optimize the conversion of an xmm register where you got your RGB values as single floats to an RGB dword integer. Especially when there's a chance that you got some floats that are too big for a DWORD I needed to do an extra minps (plus xmm2 setup for the 255.0 mask, what also costs another may be 10 Bytes) to overcome artefacts:
Any other idea to do this shorter ? May be it's even better to do that in non-SSE code as it's not speed critical anymore...
The speedup of the double pixel interleaved loop is > 400% while keeping the size, so it actually makes sense for that kind of algorithm. For others may be the overhead could be too much.
What keeps me puzzled is how to optimize the conversion of an xmm register where you got your RGB values as single floats to an RGB dword integer. Especially when there's a chance that you got some floats that are too big for a DWORD I needed to do an extra minps (plus xmm2 setup for the 255.0 mask, what also costs another may be 10 Bytes) to overcome artefacts:
Code:
;xmm1 = R|G|B|...
minps xmm1,xmm2 ;clamp to a maximum of 255.0 (xmm2=255.0|255.0|255.0|255.0
cvtps2dq xmm1,xmm1 ;int conversion
packuswb xmm1,xmm1 ;
packuswb xmm1,xmm1 ;dword to byte => 2 times needed
movd eax,xmm1
stosd ;plot pixel
Any other idea to do this shorter ? May be it's even better to do that in non-SSE code as it's not speed critical anymore...

Seems after a while of digging I solved it by myself. So the following sequence seems to do the correct conversion with no artefacts, avoiding the minps and the mask setup. Using first packssdw does the trick :-)
Code:
;xmm1 = R|G|B|...
cvtps2dq xmm1,xmm1 ;int conversion
packssdw xmm1,xmm1
packuswb xmm1,xmm1 ;dword to byte
movd eax,xmm1
stosd ;plot pixelI can confirm this. I wrote a test for this: DUMP6.ASM
Here is the result:
Here is the result:
Code:
0.5 CVTT/PACKUSWB/USWB:0 CVT/PACKUSWB/USWB:0 CVT/PACKSSDW/USWB:0
1.75 CVTT/PACKUSWB/USWB:1 CVT/PACKUSWB/USWB:2 CVT/PACKSSDW/USWB:2
34.0 CVTT/PACKUSWB/USWB:34 CVT/PACKUSWB/USWB:34 CVT/PACKSSDW/USWB:34
255.5500+ CVTT/PACKUSWB/USWB:255 CVT/PACKUSWB/USWB:255 CVT/PACKSSDW/USWB:255
256.0 CVTT/PACKUSWB/USWB:255 CVT/PACKUSWB/USWB:255 CVT/PACKSSDW/USWB:255
256.1399+ CVTT/PACKUSWB/USWB:255 CVT/PACKUSWB/USWB:255 CVT/PACKSSDW/USWB:255
65536.0 CVTT/PACKUSWB/USWB:255 CVT/PACKUSWB/USWB:255 CVT/PACKSSDW/USWB:255
16777216.0 CVTT/PACKUSWB/USWB:0 CVT/PACKUSWB/USWB:0 CVT/PACKSSDW/USWB:255
-1.0 CVTT/PACKUSWB/USWB:0 CVT/PACKUSWB/USWB:0 CVT/PACKSSDW/USWB:0
-257.0 CVTT/PACKUSWB/USWB:0 CVT/PACKUSWB/USWB:0 CVT/PACKSSDW/USWB:0
-0.01 CVTT/PACKUSWB/USWB:0 CVT/PACKUSWB/USWB:0 CVT/PACKSSDW/USWB:0
-65536.0 CVTT/PACKUSWB/USWB:0 CVT/PACKUSWB/USWB:0 CVT/PACKSSDW/USWB:0
-16777216.0 CVTT/PACKUSWB/USWB:0 CVT/PACKUSWB/USWB:0 CVT/PACKSSDW/USWB:0

I put together some information which is useful if you wanna do some sizecoding under DOS
https://www.abaddon.hu/usbdos/
https://www.abaddon.hu/usbdos/
Quote:
Still pretty sure it can be done in 10 bytes.
10 bytes:
Code:
but values 8000h..80FFh will return 0FFh.fistp word [si]
lodsw
neg ah
jz ok
shl ah,1
salc
ok:The same in 9 bytes:
Code:
fistp word [si]
lodsw
neg ah
jz ok
cwd
xchg ax,dx
ok:Quote:
Code:fistp word [si] lodsw
... if you do that repeatedly, you will overwrite your own code without precautions ;)
Yeah, of course. We assume that si is restored every time.
Else you can change it to mov ax,[si].
Else you can change it to mov ax,[si].
In the Sseraf intro, I have used a nice was to convert float->int. (SSE conversions kinda suck.)
First you add a magic constant so that your step is 1 ulp, store to memory and read the fractional bits. For example, float32bits(z∈0..255 + 2²³) = 0x4b0000zz.
What's new for me:
- You can convert not only to integer, but also to fixed-point. For example, float32bits(y∈0..1 + 2²³⁻¹⁶) = 0x4300yyyy (where y is 0.16 fixed-point).
- Normally the addition uses the current SSE rounding, but you can use the fixed-point trick to simulate a floor(): float32bits(z∈0..255.99 + 2²³⁻⁸) = 0x4700zz??. (You then read only the second-to-lowest byte).
First you add a magic constant so that your step is 1 ulp, store to memory and read the fractional bits. For example, float32bits(z∈0..255 + 2²³) = 0x4b0000zz.
What's new for me:
- You can convert not only to integer, but also to fixed-point. For example, float32bits(y∈0..1 + 2²³⁻¹⁶) = 0x4300yyyy (where y is 0.16 fixed-point).
- Normally the addition uses the current SSE rounding, but you can use the fixed-point trick to simulate a floor(): float32bits(z∈0..255.99 + 2²³⁻⁸) = 0x4700zz??. (You then read only the second-to-lowest byte).

@rrrola: Thanks for sharing ! Can you elaborate also on the packing concept algo ? I think that's the first ever 256 Byte with a code packer. You pack the first 2 bytes of each SSE instruction (into what format ?) and stick to the 0x0f encoded instructions in the entire code ?
The intro is split into two parts: only the second SSE part is packed.
All used SSE instructions look like 0F ‹opcode=28|29|5x› rm ‹optional offset›.
The packed data is split into a bitstream (commands) and a bytestream (data).
The command bits in the party version:
- 10: set XX=new byte, write 0F XX, copy one extra literal byte
- 11: write 0F XX, copy one extra literal byte
- 0: copy one literal byte
So a new SSE instruction costs 18 bits (instead of 24), an SSE instruction with a repeated opcode costs 10 bits (instead of 24), and everything else expands to 9 bits (instead of 8): loops, offsets, the esc check...
The packing method is predictable and fun to hand-optimize for: all the SSE instructions are put at the end (so that the rest doesn't expand to 9/8) and I use same-opcode chunks as much as possible.
The unpacker code is in the "tools" directory: it uses the starting registers as much as possible, and overlaps the bitstream and the bytestream. I've managed to get AH=0 after unpacking for the video mode.
All used SSE instructions look like 0F ‹opcode=28|29|5x› rm ‹optional offset›.
The packed data is split into a bitstream (commands) and a bytestream (data).
The command bits in the party version:
- 10: set XX=new byte, write 0F XX, copy one extra literal byte
- 11: write 0F XX, copy one extra literal byte
- 0: copy one literal byte
So a new SSE instruction costs 18 bits (instead of 24), an SSE instruction with a repeated opcode costs 10 bits (instead of 24), and everything else expands to 9 bits (instead of 8): loops, offsets, the esc check...
The packing method is predictable and fun to hand-optimize for: all the SSE instructions are put at the end (so that the rest doesn't expand to 9/8) and I use same-opcode chunks as much as possible.
The unpacker code is in the "tools" directory: it uses the starting registers as much as possible, and overlaps the bitstream and the bytestream. I've managed to get AH=0 after unpacking for the video mode.
Stats for the party version:
Code:
'0F RR xx' * 24: 72 -> 30 bytes
'0F NN xx' * 18: 54 -> 40.5 bytes
'xx' * 39: 39 -> 43.875 bytes
Packed: 165 -> 114.375 bytes, rounded down (3 bits merged with the bytestream)
Not packed: 28 (unpacker) + 114 bytes (intro code)
114 + 28 + 114 = 256@rrrola: Thanks for the additional details! Very nice to see these concepts providing benefits.
For x86 and tiny code footprints the separation of bit and bytestreams is the best option (except for byte based packers ofc).
@all: Since it seemed to be kind of a surprise to some sizecoders at the sizecoding discord:
BT (bit test) and its variants are able to address a bitfield with 2^16 bits or more (depending on register width) using a single index.
For x86 and tiny code footprints the separation of bit and bytestreams is the best option (except for byte based packers ofc).
@all: Since it seemed to be kind of a surprise to some sizecoders at the sizecoding discord:
BT (bit test) and its variants are able to address a bitfield with 2^16 bits or more (depending on register width) using a single index.
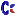
BT [mem],reg
The index in reg is signed: the lowest bit has index 0.
The instruction accesses the whole 16-bit (or 32-bit) word even when it needs only one bit.
The index in reg is signed: the lowest bit has index 0.
The instruction accesses the whole 16-bit (or 32-bit) word even when it needs only one bit.
Tailored to the intro or not, this comes close to first real packer for 256b bytes, strong!
I'm as well guilty of not knowing that the bit testing index can skyrocket when used on memory xD
Please do join us on the sizecoding discord =)
I'm as well guilty of not knowing that the bit testing index can skyrocket when used on memory xD
Please do join us on the sizecoding discord =)
@HellMood: For x86 it's a first I think. introspec for example did this on Z80 already (as he mentioned on the Discord):
https://www.pouet.net/prod.php?which=63073
https://www.pouet.net/prod.php?which=63073