
is anyone who's having same problem as this?
category: code [glöplog]
this is what i wanted:

and this is what i got:

and this is what i got:

I don't see a problem, the second one is a lot more interesting.

New effect :)
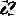
probs about numerical precision

Your lack of information is disturbing.
+1 what preacher said
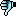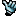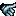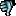
you need to click the mouse harder.

4x8 tiles is how threads of a fragment shader are grouped in the image plane on nvidia. they call it a "warp" and all threads of a warp run the same instruction at any time, just with different data, which is why the image seems to be coherent inside each 4x8 block. You seem to have a concurrency problem, caused by reading some data that is dependent on other warps' output and using that data in a branch condition. scattered writes that are read by the same shader or something. try using two buffers/textures, one for reading and one for writing.
But then again, the picture IS more interesting.
Bonus: you can see how a tiny bit of perf is wasted at the diagonal that separates the screen-space quad into two triangles: every 4x8 block that is split by the diagonal will be executed twice while those pixels on one side of the diagonal are discarded. You could draw a single large triangle that covers much more than the whole screen and let automatic clipping cut off the parts outside. instant 0.5% speedup!
But then again, the picture IS more interesting.
Bonus: you can see how a tiny bit of perf is wasted at the diagonal that separates the screen-space quad into two triangles: every 4x8 block that is split by the diagonal will be executed twice while those pixels on one side of the diagonal are discarded. You could draw a single large triangle that covers much more than the whole screen and let automatic clipping cut off the parts outside. instant 0.5% speedup!

this is not true beginning with maxwell tho, it seems to rasterize everything and schedule afterwards in some manner (judging by the good old "atomic increment to see pixel shading order" test)
oh and btw i have
windows 10 64bit
intel(r) pentium(r) cpu g3240 @ 3.10ghz
windows 10 64bit
intel(r) pentium(r) cpu g3240 @ 3.10ghz
and my graphics card are nvidia
Quote:
You seem to have a concurrency problem, caused by reading some data that is dependent on other warps' output and using that data in a branch condition.
I'm guessing the same texture is used as input and output?

looks like an uninitialized var to me

@cupe: Back when I did GPGPU, I measured the “large triangle” vs. “quad” over something like ten different GPUs. None showed a measurable difference. (IIRC, most just clipped the quad back into a triangle.)
There was a neat blogpost about this a while ago w.r.t. the GCN architecture:
https://michaldrobot.com/2014/04/01/gcn-execution-patterns-in-full-screen-passes/
The triangle "trick" is known for a long time - it also avoids possible problems with screen-space derivatives along the diagonal of the screen.
https://michaldrobot.com/2014/04/01/gcn-execution-patterns-in-full-screen-passes/
The triangle "trick" is known for a long time - it also avoids possible problems with screen-space derivatives along the diagonal of the screen.

Quote:
this is not true beginning with maxwell tho
alright, didn't know that. don't mind me peasant with my humble kepler titan (which died. sigh.)
Quote:
@cupe: Back when I did GPGPU, I measured the “large triangle” vs. “quad” over something like ten different GPUs. None showed a measurable difference. (IIRC, most just clipped the quad back into a triangle.)
That's what I meant with the 0.5% speedup. Any difference (if there was one) got lost in the noise for me as well. Also, correction to what I said above: I remember something about that overhanging pixels of a warp being re-shuffled at quad granularity, so the warp can be some other shape instead of a 4x8-block. Which is probably why I couldn't measure any difference back then, come to think of it. No idea what the rules are for that happening.
I can second provod on this, in the past year nvidia changed something in their driver related to uninitialized variables. I suspect they used to initialize them to zero, and now they don't. To be fair, they do show a compiler warning.
I have the same problem in this prod, which now looks like this:

I did manage to fix it and beat the size back to 1K, but I don't have a Windows 10 machine to test. Can anyone test these versions on Windows 10 and let me know if they work? If so, I can update the archive and product page.
I have the same problem in this prod, which now looks like this:
I did manage to fix it and beat the size back to 1K, but I don't have a Windows 10 machine to test. Can anyone test these versions on Windows 10 and let me know if they work? If so, I can update the archive and product page.

Both versions silently crash on Windows 10 on my machine (GTX960)
Sig[0].Name=Application Name
Sig[0].Value=test_720.exe
Sig[1].Name=Application Version
Sig[1].Value=0.0.0.0
Sig[2].Name=Application Timestamp
Sig[2].Value=eb2da30f
Sig[3].Name=Fault Module Name
Sig[3].Value=user32.DLL
Sig[4].Name=Fault Module Version
Sig[4].Value=10.0.14393.576
Sig[5].Name=Fault Module Timestamp
Sig[5].Value=584a7a33
Sig[6].Name=Exception Code
Sig[6].Value=c0000005
Sig[7].Name=Exception Offset
Sig[7].Value=00012f1b
Sig[0].Name=Application Name
Sig[0].Value=test_720.exe
Sig[1].Name=Application Version
Sig[1].Value=0.0.0.0
Sig[2].Name=Application Timestamp
Sig[2].Value=eb2da30f
Sig[3].Name=Fault Module Name
Sig[3].Value=user32.DLL
Sig[4].Name=Fault Module Version
Sig[4].Value=10.0.14393.576
Sig[5].Name=Fault Module Timestamp
Sig[5].Value=584a7a33
Sig[6].Name=Exception Code
Sig[6].Value=c0000005
Sig[7].Name=Exception Offset
Sig[7].Value=00012f1b

Seven: That's a very bad news :(
bloodnok: thanks for testing, guess I'll have to Crinkler-compress it on a Windows 10 machine because the TINY-INTRO option is OS-dependant. I hope the result is still 1K...
Flashy: Are you talking about your original problem? Initializing the variable shouldn't take more than 2-3 bytes, which usually is not a problem in 4Ks or bigger. Check your shader compilation output to find the problematic variable. It's a nuisance that the nvidia driver is once again pickier than the AMD one, but not what I would call very bad news.
Flashy: Are you talking about your original problem? Initializing the variable shouldn't take more than 2-3 bytes, which usually is not a problem in 4Ks or bigger. Check your shader compilation output to find the problematic variable. It's a nuisance that the nvidia driver is once again pickier than the AMD one, but not what I would call very bad news.
I mean the /TINYIMPORT option, obviously. /TINYINTRO would be redundant for Crinkler :)
I've tried a crinkler /recompress on it and running it in win7 compat mode... same result in both cases
.
.
@Seven: your test runs fine on my Win10 (1511) with my pretty slow 940MX an 381.65 driver. but i really like the glitch in original release ;-)
bloodnok: the Crinkler documentation doesn't mention this explicitly, but I think /TINYIMPORT does not store enough info about the needed DLLs and functions to fix conflicting imports on different machines. Everything is hashed. Maybe Blueberry can chip in if he sees this. Can you tell me which version of Windows 10 you have? I'll need to find a machine with the same version, and then hope that the generated exe still works find in Windows 7...
RufUsul: thanks for testing, good to know the version of Windows 10 makes a difference as well!
RufUsul: thanks for testing, good to know the version of Windows 10 makes a difference as well!
Windows 10 Pro v1607 (build 14393.1593)