
Coding as art?
category: general [glöplog]
! hundert !
(and i really like that rotzoom-avatar)
(and i really like that rotzoom-avatar)


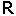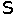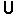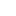
rotozoom 4 eva
Especially the cache-optimized swizzled kind :)
Especially the cache-optimized swizzled kind :)

rept 8
mov al, [esi+0x11111111]
mov ah, [esi+0x22222222]
mov bl, [esi+0x33333333]
mov bh, [esi+0x44444444]
shl ax, 16
shl bx, 16
mov al, [esi+0x55555555]
mov ah, [esi+0x66666666]
mov bl, [esi+0x77777777]
mov bh, [esi+0x88888888]
mov [edi+p],eax
mov [edi+p+4],ebx
p=p+pitch
endm
art?
mov al, [esi+0x11111111]
mov ah, [esi+0x22222222]
mov bl, [esi+0x33333333]
mov bh, [esi+0x44444444]
shl ax, 16
shl bx, 16
mov al, [esi+0x55555555]
mov ah, [esi+0x66666666]
mov bl, [esi+0x77777777]
mov bh, [esi+0x88888888]
mov [edi+p],eax
mov [edi+p+4],ebx
p=p+pitch
endm
art?

i know.. spot the bug
How very interesting, I lost count of the partial register stalls :)
Nope, not quite art...
As for the bug, I assume you meant to update esi aswell? Then the code would be less totally useless :)
And well x86 can never be art, since it's just ugly crap :)
Nope, not quite art...
As for the bug, I assume you meant to update esi aswell? Then the code would be less totally useless :)
And well x86 can never be art, since it's just ugly crap :)
bzzt. there are 64 "constants" instead of 8 ;)
the bug is in shl which could be better paired too. (move first 2 up another 1 down)
the bug is in shl which could be better paired too. (move first 2 up another 1 down)
Pairing is not the problem here, it stalls like shit on a modern CPU, because of the partial register stalls...
Modern CPUs can schedule for themselves (PPRO and up have ooo execution)...
I guess you are still stuck in the Pentium age, when pairing had to be done manually, and there was no partial register stall problem yet :)
Modern CPUs can schedule for themselves (PPRO and up have ooo execution)...
I guess you are still stuck in the Pentium age, when pairing had to be done manually, and there was no partial register stall problem yet :)
on machines with such probs you can often do:
glBegin(GL_POLYGON);
glTexCoord2d(a, b); glVertex2d(0, 0);
glTexCoord2d(-b, a); glVertex2d(0, 1);
glTexCoord2d(-a, -b); glVertex2d(1, 1);
glTexCoord2d(a, -b); glVertex2d(1, 0);
glEnd();
glBegin(GL_POLYGON);
glTexCoord2d(a, b); glVertex2d(0, 0);
glTexCoord2d(-b, a); glVertex2d(0, 1);
glTexCoord2d(-a, -b); glVertex2d(1, 1);
glTexCoord2d(a, -b); glVertex2d(1, 0);
glEnd();
How wonderfully efficient...
Gotta love OGL ;)
Gotta love OGL ;)
By the way, afaik the first cache-optimized rotozoomer was done on Amiga (by Komplex?)...
And later converted to PC by Cubic, if I'm not mistaken.
And later converted to PC by Cubic, if I'm not mistaken.
didn't i say something about glVertex() ?
shl ax, 16
nice, nice
nice, nice

drat, perhaps it would be a good idea to read the other comments as well :)
Ah, yes, didn't even see that one :)
besides, why would you want to have something like swizzle-precalc optimized in ASM?
Have too much time on your hands? :)
chaos: Dunno, what did you say? :)
And what did nVidia say in their PDFs?...
Hrm... something with a b...
Batch?
:)
besides, why would you want to have something like swizzle-precalc optimized in ASM?
Have too much time on your hands? :)
chaos: Dunno, what did you say? :)
And what did nVidia say in their PDFs?...
Hrm... something with a b...
Batch?
:)
i think what's being suggested is to wrap one full-screen quadrilateral into a set of bounded striped vertex and index arrays of optimal size, drawn using few calls as opposed to flooding the bottleneck with several calls per vertex and possibly cache the whole bunch of crap into display lists in case the vertices aren't being moved in a non-linear way?









