
Sweep line algorithm
category: code [glöplog]
Hey everyone,
Well i'm trying to implement a fast way to find intersected areas for random boxes in 2d plane usually i would do 2 pass loops which will result O(n^2) and this dropped fps a lot so i tried to optimize it by using Sweep line algorithm to gain O((n+k)log n) so far i want to do something like this:

the initial idea is to sort all points in x-axis and y-axis then start sweeping on x-axis if there is intersection start sweeping in y-axis if there is no intersection on y-axis then ignore it.
after trying it i found that i end up in O(n^2) =\ either i used the algorithm in wrong way or there are something missing about.
i'll appreciate anyhelp D:
thanks
Well i'm trying to implement a fast way to find intersected areas for random boxes in 2d plane usually i would do 2 pass loops which will result O(n^2) and this dropped fps a lot so i tried to optimize it by using Sweep line algorithm to gain O((n+k)log n) so far i want to do something like this:
the initial idea is to sort all points in x-axis and y-axis then start sweeping on x-axis if there is intersection start sweeping in y-axis if there is no intersection on y-axis then ignore it.
after trying it i found that i end up in O(n^2) =\ either i used the algorithm in wrong way or there are something missing about.
i'll appreciate anyhelp D:
thanks
didn't quite get what you want, but sweeping like you would do in your picture is not very cashe effective. top to bottom is the way to go.

Hello Panic,
if it goes to quadratic, then there's surely something you're doing wrong.
Are you sure that you just process every event just once?
How are you storing the resulting intersection of boxes?
Basically the events list must also be sorted to achieve logarithmic access.
I'm guessing that what you want is the shape of the intersection.
if it goes to quadratic, then there's surely something you're doing wrong.
Are you sure that you just process every event just once?
How are you storing the resulting intersection of boxes?
Basically the events list must also be sorted to achieve logarithmic access.
I'm guessing that what you want is the shape of the intersection.

whynot2000: the direction of the sweeping line doesn't matter.
whynot2000: well i am trying to find the area of all rectangles without computing the intersected areas more than once.
Dario Phong:
Are you sure that you just process every event just once?
for X-axis yes.
How are you storing the resulting intersection of boxes?
well i am using for now a balanced tree (AVL for now)
well i am using heapsort.
not sure what is the missing thing about anyhint?
Dario Phong:
Are you sure that you just process every event just once?
for X-axis yes.
How are you storing the resulting intersection of boxes?
well i am using for now a balanced tree (AVL for now)
well i am using heapsort.
not sure what is the missing thing about anyhint?
here is a test code for what i did so far:
Code:
for (int i = 1; i < e; ++i) { // Vertical sweep line
event c = events_x[i];
int count = 0; // Counter to indicate how many rectangles are currently overlapping
// Delta_x: Distance between current sweep line and previous sweep line
int delta_x = rects[c.index][c.type].x - rects[events_x[i - 1].index][events_x[i - 1].type].x;
int begin_y;
if (delta_x == 0) continue;
for (int j = 0; j < e; ++j) {
if (queue[events_y[j].index] == 1) { // Horizontal sweep line
if (events_y[j].type == 0) {
if (count == 0) begin_y = rects[events_y[j].index][0].y; // Block starts
++count;
} else {
--count;
if (count == 0) { // Block ends
int delta_y = (rects[events_y[j].index][1].y - begin_y);
area += delta_x * delta_y;
}
}
}
}
queue[c.index] = (c.type == 0);
}
Sounds like Home work
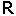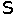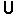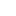
@Panic:
If what you do is to find all the intersections for all the squares, it is a must that the algorithm is O(N^2) for its worst case.
Suppose you have 1,000 rectangles, all on top of each other and all overlapping each other. This is a worst case and you will have O(N^2) just to write the output.
So, first, define what you exactly need. Do you need an average O better than N^2? In what case? Tell us about the distribution of your rectangles. Tell us about the average size, distribution in size of them and the plane area where they are going to be disposed.
If what you do is to find all the intersections for all the squares, it is a must that the algorithm is O(N^2) for its worst case.
Suppose you have 1,000 rectangles, all on top of each other and all overlapping each other. This is a worst case and you will have O(N^2) just to write the output.
So, first, define what you exactly need. Do you need an average O better than N^2? In what case? Tell us about the distribution of your rectangles. Tell us about the average size, distribution in size of them and the plane area where they are going to be disposed.
rasmus/loonies: lol not a HW =\.
texel: Well as you said i knew the worst case about it which is all rectangles intersects each other BUT in my case it showed it is very odd to happen.
after doing number of test on the algorithm which generates them it showed:
~45% of rectangles intersect each other (8~12% overlapped by others)
rest are isolated.
the algorithm which generates them is a randomized with some rules to control
so if i could at least have O(n log n) for the rest of them (55%) that would be nice.
but if implementing this would take more time to get it working i might reconsider it.
texel: Well as you said i knew the worst case about it which is all rectangles intersects each other BUT in my case it showed it is very odd to happen.
after doing number of test on the algorithm which generates them it showed:
~45% of rectangles intersect each other (8~12% overlapped by others)
rest are isolated.
the algorithm which generates them is a randomized with some rules to control
so if i could at least have O(n log n) for the rest of them (55%) that would be nice.
but if implementing this would take more time to get it working i might reconsider it.
Ok, one idea:
I would use a grid to divide the area where the rectangles are. For example, a 10x10 or 100x100 grid.
On each cell of the grid I would place a list of the rectangles that fully or partially cover them.
Checking intersections this way would be faster if the distribution of rectangles is random, they don't cover very big surfaces and there are a good number of them.
I suppose a sweep line algo might be even more efficient, but definitely more difficult to code.
I would use a grid to divide the area where the rectangles are. For example, a 10x10 or 100x100 grid.
On each cell of the grid I would place a list of the rectangles that fully or partially cover them.
Checking intersections this way would be faster if the distribution of rectangles is random, they don't cover very big surfaces and there are a good number of them.
I suppose a sweep line algo might be even more efficient, but definitely more difficult to code.
So the majority of overlaps or zero or one overlaps?
If the rectangles are small compared to the entire area a quadtree (or similar 2d partitions) approach should do well for finding isolated rectangles and, in case of overlapping, the overlapping rectangles. Would be n log n for non-overlapping and single overlapping rectangles, and worst case n log n * m^2 determined by the maximum entry / overlap count m inside a tree leaf.
In case of large rectangles, a similar tree aproach might work well, but by splitting new rectangles into their non-overlapping parts when compared with the already contained rectangles during quadtree construction in order to reduce the maximum child count
If the rectangles are small compared to the entire area a quadtree (or similar 2d partitions) approach should do well for finding isolated rectangles and, in case of overlapping, the overlapping rectangles. Would be n log n for non-overlapping and single overlapping rectangles, and worst case n log n * m^2 determined by the maximum entry / overlap count m inside a tree leaf.
In case of large rectangles, a similar tree aproach might work well, but by splitting new rectangles into their non-overlapping parts when compared with the already contained rectangles during quadtree construction in order to reduce the maximum child count

what the fuck am I doing 2 am in the night after christmas eve, completely stuffed with duck, tired after a long day, trying to solve a sweepline algorithm problem when I don't really want to be a computer programmer any more...

Then be a gameboy advance programmer :P

Is there something better than a Pouët Christmas Eve?
texel : hmmm
Well your idea if i used a simple scanning to check intersect boxes in each grid cell will be O( m * n ) as a start where m = number of cells , n=boxes.
what am i thinking about is to use 2 intervals trees one for X and the other for Y
in such way the complexity will be m * 2 * log n
but scanning each cell will be O(w^2) where w is number of rectangles?
anyideas?
thanks
Well your idea if i used a simple scanning to check intersect boxes in each grid cell will be O( m * n ) as a start where m = number of cells , n=boxes.
what am i thinking about is to use 2 intervals trees one for X and the other for Y
in such way the complexity will be m * 2 * log n
but scanning each cell will be O(w^2) where w is number of rectangles?
anyideas?
thanks
texel: The O(n^2) worst case is the wrong way to look at the complexity, and bringing statistical properties of your input data into the problem specification is overkill.
A good solution for this problem ought to be output-sensitive: Its running time should depend on the number of intersections in the dataset. This is usually denoted by k, as in panics original post - he's looking for something that runs in O((n+k) log n).
panic: You're doing the sweep the wrong way. You only ever sweep on one axis! If you need to start a secondary sweep for every event point, you've already lost!
Say you sweep along the x axis. During the sweep, you keep track of all rectangles that currently intersect the sweep line. You can directly keep track of their y-intersections with something like an interval tree.
There's two kinds of event points, "start rectangle" and "end rectangle". On "start rectangle", you need to add the y-interval for this rectangle to the interval tree, and on "end rectangle", you delete it again. During insertion, keep track of all existing y-intervals the new y-interval intersects with (this is fairly straightforward from the interval tree structure).
There's some work and additional data structures involved in actually reporting the intersection rectangles. I leave that as an exercise to the reader :)
A good solution for this problem ought to be output-sensitive: Its running time should depend on the number of intersections in the dataset. This is usually denoted by k, as in panics original post - he's looking for something that runs in O((n+k) log n).
panic: You're doing the sweep the wrong way. You only ever sweep on one axis! If you need to start a secondary sweep for every event point, you've already lost!
Say you sweep along the x axis. During the sweep, you keep track of all rectangles that currently intersect the sweep line. You can directly keep track of their y-intersections with something like an interval tree.
There's two kinds of event points, "start rectangle" and "end rectangle". On "start rectangle", you need to add the y-interval for this rectangle to the interval tree, and on "end rectangle", you delete it again. During insertion, keep track of all existing y-intervals the new y-interval intersects with (this is fairly straightforward from the interval tree structure).
There's some work and additional data structures involved in actually reporting the intersection rectangles. I leave that as an exercise to the reader :)

captain obvious: http://en.wikipedia.org/wiki/Sweep_line_algorithm
also, i recall doing something similar for a home assignment at uni during computational geometry course. as ryg stated, it's a matter of bringing enough data structures into work to bring the complexity to O((n+k)log n).
the wikipedia article links to an implementation article for line segment sweeps, this could be expanded to rectangles, triangles, etc.
if you were looking at rendering the stuff, i'd suggest to have a go at span/coverage buffers.
http://www.flipcode.com/archives/Harmless_Algorithms-Issue_01_Fine_Occlusion_Culling_Algorithms.shtml#bst
http://www.flipcode.com/archives/The_Coverage_Buffer_C-Buffer.shtml
also, i recall doing something similar for a home assignment at uni during computational geometry course. as ryg stated, it's a matter of bringing enough data structures into work to bring the complexity to O((n+k)log n).
the wikipedia article links to an implementation article for line segment sweeps, this could be expanded to rectangles, triangles, etc.
if you were looking at rendering the stuff, i'd suggest to have a go at span/coverage buffers.
http://www.flipcode.com/archives/Harmless_Algorithms-Issue_01_Fine_Occlusion_Culling_Algorithms.shtml#bst
http://www.flipcode.com/archives/The_Coverage_Buffer_C-Buffer.shtml
Ryg, thanks so much for the explanation. Now that k makes much more sense :D
I've been thinking in a space partitioning tree:
- All the plane cuts are vertical or horizontal. Odd depth cuts are all horizontal, even are all vertical, just like in kd-trees
- Differently from kd-trees, there could be more than 1 cuts, an unlimited number of these. They could be ordered
- In the leaf nodes we could have empty, one rectangle or a list of intersected rectangles.
- All the plane cuts are vertical or horizontal. Odd depth cuts are all horizontal, even are all vertical, just like in kd-trees
- Differently from kd-trees, there could be more than 1 cuts, an unlimited number of these. They could be ordered
- In the leaf nodes we could have empty, one rectangle or a list of intersected rectangles.
Oh... it seems that a kd-tree could work too... But then the problem would be how to generate a good one... it doesn't seems like an easy thing...
texel: Standard data structure for set operations on rectangles is the "shape" data structure (commonly used for implementation of arbitrarily shaped clipping regions). Partition space into y-"stripes". Per stripe, you store a list of all x-intervals contained in the region.
Invariants:
There's several ways to implement this. The usual implementation is a linked list of linked lists, but you can use trees if you want better asymptotic complexity, or arrays if you want somewhat simpler code.
This representation is canonical (i.e. two regions are identical if and only if their representations agree) and you can implement all the basic set operations (union, intersection, difference, symmetric difference) in a fairly straightforward way (it's always the same basic algorithm with different rules about which x-intervals to keep). It's not hard, but somewhat tedious.
Invariants:
- The y-stripes are nonoverlapping and stored in order of increasing start y coordinate.
- Inside every y-stripe, all the x-intervals are nonoverlapping and sorted in order of increasing start x coordinate.
- Inside a y-stripe, there are never any abutting x-intervals (e.g. [a,b] [b,c]) - they are coalesced (into [a,c]) as soon as they are created.
- Likewise, if two abutting y-stripes share the same list of occupied x-intervals, they are coalesced into one.
There's several ways to implement this. The usual implementation is a linked list of linked lists, but you can use trees if you want better asymptotic complexity, or arrays if you want somewhat simpler code.
This representation is canonical (i.e. two regions are identical if and only if their representations agree) and you can implement all the basic set operations (union, intersection, difference, symmetric difference) in a fairly straightforward way (it's always the same basic algorithm with different rules about which x-intervals to keep). It's not hard, but somewhat tedious.
ryg:
so i'll try to recap it into simple steps (plz correct me if i got it wrong!):
1) sort all start/end points (X-axis) for all rectangles .
2) sweep along x-axis.
3) at any event if it is a start of rectangle then adds its y-interval (start/end of y) and at end of rectangle remove that interval.(?)
4) if intersect found between start/end of the sweep see if these two intersected points in x-axis and check their y-intervals and see if they intersect(not sure from this point..)
is there anything missing or wrong on them?
thanks everyone for trying to help me :)
Quote:
There's two kinds of event points, "start rectangle" and "end rectangle". On "start rectangle", you need to add the y-interval for this rectangle to the interval tree, and on "end rectangle", you delete it again. During insertion, keep track of all existing y-intervals the new y-interval intersects with (this is fairly straightforward from the interval tree structure).
so i'll try to recap it into simple steps (plz correct me if i got it wrong!):
1) sort all start/end points (X-axis) for all rectangles .
2) sweep along x-axis.
3) at any event if it is a start of rectangle then adds its y-interval (start/end of y) and at end of rectangle remove that interval.(?)
4) if intersect found between start/end of the sweep see if these two intersected points in x-axis and check their y-intervals and see if they intersect(not sure from this point..)
is there anything missing or wrong on them?
thanks everyone for trying to help me :)
panic: 3) correct.
4) you don't check for intersections along the x-axis at all, all x axis processing is implicit in the sweep.
you automatically discover intersections when adding new intervals to the interval tree (the intersection determination is part of the insertion processing). when you discover an intersection between two rectangles, you keep note of which two rectangles are intersecting. once you reach the end of one of the two intersecting rectangles, you know the extents of the intersection rectangle.
4) you don't check for intersections along the x-axis at all, all x axis processing is implicit in the sweep.
you automatically discover intersections when adding new intervals to the interval tree (the intersection determination is part of the insertion processing). when you discover an intersection between two rectangles, you keep note of which two rectangles are intersecting. once you reach the end of one of the two intersecting rectangles, you know the extents of the intersection rectangle.
AH HA so i see
simple move ur sweep line a long x-axis if start of rectangle found add its y-interval in tree if you added and found it already exist in a created interval (of others) then note them in as rect A intersect B hence this indecents the K in
O( N+K log n)
at end of rect remove it y-interval.
loop K and compute areas
Done!
right D:?
Thanks in advanced!!
simple move ur sweep line a long x-axis if start of rectangle found add its y-interval in tree if you added and found it already exist in a created interval (of others) then note them in as rect A intersect B hence this indecents the K in
O( N+K log n)
at end of rect remove it y-interval.
loop K and compute areas
Done!
right D:?
Thanks in advanced!!

