Crinkler & shaders: how to achieve the best compression ratio?
category: code [glöplog]
I'd like to open a discussion about the shaders compression in Crinkler. First, I've noticed that macros like "#define r return" are counterproductive and result in bigger compressed code (no matter how many macros I inserted, it was bad).
For the variables names, I decided to use first the most used letters in the rest of the code. Then, I wondered if I should name a variable "W" (where "W" is an unused letter), or "ee" (where "e" is the most letter), or "fl" (where "fl" is the most frequent bigram in the code). I found that single letters were the best choice. Then, it was better to combine most frequent letters, instead of using the most frequent bigrams (that surprised me).
That's the strategy currently used in GLSL Minifier. It works quite well, although I believe it's possible to improve it. I had a quick look at the PAQ compression, but some of you might have already tried different strategies, or have suggestions?
At some point, I thought I could use the type information, as variables of similar type are more likely to be used in the same way. But, I can go further: For each letter, I can look in which context it's used (and give the same name to things used in similar contexts).
Which size is the context used in Crinkler to predict the next bit? Should the naming of variables depend on the binary representation of the letters? Does it make sens to do the analysis on the bits - or looking at bytes (i.e. characters) is enough?
In a future version of GLSL Minifier, I will also try to inline and remove variables when it's possible. For instance, in the expression "float f = 4. * x; return f;" the variable f could be removed. This will require a more complex analysis, and a detection of side-effects.
For the variables names, I decided to use first the most used letters in the rest of the code. Then, I wondered if I should name a variable "W" (where "W" is an unused letter), or "ee" (where "e" is the most letter), or "fl" (where "fl" is the most frequent bigram in the code). I found that single letters were the best choice. Then, it was better to combine most frequent letters, instead of using the most frequent bigrams (that surprised me).
That's the strategy currently used in GLSL Minifier. It works quite well, although I believe it's possible to improve it. I had a quick look at the PAQ compression, but some of you might have already tried different strategies, or have suggestions?
At some point, I thought I could use the type information, as variables of similar type are more likely to be used in the same way. But, I can go further: For each letter, I can look in which context it's used (and give the same name to things used in similar contexts).
Which size is the context used in Crinkler to predict the next bit? Should the naming of variables depend on the binary representation of the letters? Does it make sens to do the analysis on the bits - or looking at bytes (i.e. characters) is enough?
In a future version of GLSL Minifier, I will also try to inline and remove variables when it's possible. For instance, in the expression "float f = 4. * x; return f;" the variable f could be removed. This will require a more complex analysis, and a detection of side-effects.

well i did some wired shit a while ago with a small grammer that always repaces strings according to some rules until only terminal symboles are left in the string. using the buildin preprocessor could still be more beneficial, if used correctly.

crinkler is using a context order of 1 to 8 byte (those "mask-models" are the one selected by crinkler while compressing). It's not a surprised that bigrams are less efficient than single letters, since false bigrams (like "fl") are perturbating probabilities for real one ("fl(oat)").
For #define, they could compress well when the definition of your function is much smaller using a #define than a plain glsl declaration... otherwise It wont help on substitution... context modeling is much more efficient at this "template substitution". Although, using #define in certain case is helping a lot to templatize large portion of the code...
For byte vs bits, well, you have probably to take care of both! ;) I guess that selecting letters that have a larger sequence of common bits could help, but you have to check it...
For #define, they could compress well when the definition of your function is much smaller using a #define than a plain glsl declaration... otherwise It wont help on substitution... context modeling is much more efficient at this "template substitution". Although, using #define in certain case is helping a lot to templatize large portion of the code...
For byte vs bits, well, you have probably to take care of both! ;) I guess that selecting letters that have a larger sequence of common bits could help, but you have to check it...

Thanks a lot!
After some experimentation, I got interesting results. Instead of reusing always the same names (which increased the frequency of some letters), my tool now uses the context in which variables are used. The goal is to increase the frequency of bigrams. At the end, the shader compresses even better (~10 bytes on average).
I have updated GLSL Minifier today and tried it on real 4k intros. It was able to save 41 bytes on Retrospection, 56 bytes on Valleyball, 48 bytes on the pre-release version of Another Theory. I'd love to get more data and see what I could improve.
See more detailed stats
I have updated GLSL Minifier today and tried it on real 4k intros. It was able to save 41 bytes on Retrospection, 56 bytes on Valleyball, 48 bytes on the pre-release version of Another Theory. I'd love to get more data and see what I could improve.
See more detailed stats
Brief thread derail: Why aren't shaders compiled into an intermediate binary (like MSIL or Java Bytecode)? Are what nvidia and amd do so radically different that such a thing is impossible? Wasn't HLSL converted into assembly at one point?

HLSL was (and still is) compiled into a bytecode which is then translated by the driver. The idea is sound, the problem is just that the HLSL compiler tries to do a lot of optimizations (minimizing number of registers used, everything gets inlined, loop unrolling, conditional stripping, etc.) that drivers then partially or fully undo to actually generate code for the target hardware.
It'd make life easier for drivers (and shorten compile times considerably) if the HLSL compiler tried a little less hard :)
It'd make life easier for drivers (and shorten compile times considerably) if the HLSL compiler tried a little less hard :)

word
@QUINTIX, afair, generated bytecode from HLSL is usually much larger than optimized HLSL itself, and also doesn't compress as well...
Nice one LLB!

ryg: I believe he meant why aren't they compiled before runtime, i.e. included in the binary as binary themselves rather than packed ASCII. But yes, those compilers really do try way too hard :) .
Also, what @lx said.
Also, what @lx said.
and then the drivers, like ryg said, spend a lot of time 'deoptimizing' and recompiling the bytecode which in turn spawns a whole new hurdle if you actually have a lot of them (i.e in a game)

"and then the drivers, like ryg said, spend a lot of time 'deoptimizing' and recompiling the bytecode which in turn spawns a whole new hurdle if you actually have a lot of them (i.e in a game)"
well the "deoptimization" doesn't take much time - it's basically just the driver converting the code into its own IR, which destroys things like the exact register assignment. it's just pointless for the HLSL compiler to be spending a lot of time trying to find the "optimal" unroll level for loops etc. when it doesn't know what HW it's targeting, what the scheduling constraints (or even actual microcode instructions) are, or even how the number of registers used influences performance. it just makes compilation of dynamic branch-intensive shaders take forever and a day without actually being useful to anyone :)
well the "deoptimization" doesn't take much time - it's basically just the driver converting the code into its own IR, which destroys things like the exact register assignment. it's just pointless for the HLSL compiler to be spending a lot of time trying to find the "optimal" unroll level for loops etc. when it doesn't know what HW it's targeting, what the scheduling constraints (or even actual microcode instructions) are, or even how the number of registers used influences performance. it just makes compilation of dynamic branch-intensive shaders take forever and a day without actually being useful to anyone :)
preach!
yeah 'recompiling' was to be interpreted loosely :)
Shader Minifier (yes, that's the new name) now supports HLSL. You should all use it now - even Elevated would be smaller by using this tool!
(detailed statistics will come later)
(detailed statistics will come later)
Sounds as if that tool will save me a lot of time ;)
Nice job - I'll give it a try.
Nice job - I'll give it a try.

url please

too late :D
whilst i like the tool - i also find the stats demotivating. from what i see you only gain 3-10 bytes using this tool. that's not massive :-)
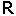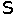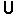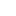
How can a tool that does better than hand-optimizing a shader file NOT be useful? Just wondering...
rasmus: It depends on shaders.
If you use Shader Minifier on an already optimized shader, you can save up to 50 bytes. For instance, try it on Cdak (shader extracted from their release). It removes 109 bytes on the uncompressed shader, which become 41 bytes after Crinkler compression. I think that's not bad.
Sure, it's not perfect and it might sometimes give you a bigger result - but you can often fix it by hand to get best compression ratio.
Anyway, it also saves time.
If you use Shader Minifier on an already optimized shader, you can save up to 50 bytes. For instance, try it on Cdak (shader extracted from their release). It removes 109 bytes on the uncompressed shader, which become 41 bytes after Crinkler compression. I think that's not bad.
Sure, it's not perfect and it might sometimes give you a bigger result - but you can often fix it by hand to get best compression ratio.
Anyway, it also saves time.
@LLB
is it for party version or the final?
party version was fairly unoptimized=)
is it for party version or the final?
party version was fairly unoptimized=)
